


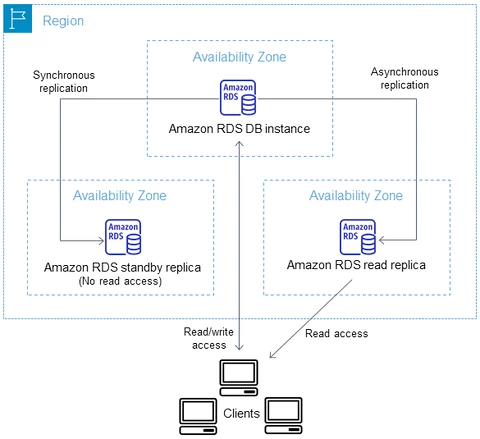
.png)

Nov 07, 2024
Nov 07, 2024
Mastering the ISTQB Foundation Level: Essential Tips and Tricks
The ISTQB Foundation Level (FL) certification is a valuable milestone for anyone pursuing a career in software testing. It provides a solid grounding in fundamental testing principles and practices, making it a key certification for beginners and seasoned professionals alike. If you’re preparing for the ISTQB FL exam, here are some essential tips and tricks to help you navigate your study journey and boost your chances of success.

