![HTTP Adventure: [Part 2] The evolution of HTTP/2](/images/blog/detail-shape-heading.webp)
![HTTP Adventure: [Part 2] The evolution of HTTP/2](https://static-careers.moneyforward.vn/Blog/HTTP%20series/%5BPart%202%5D%20The%20evolution%20of%20HTTP2.png)





Aug 26, 2025
Aug 26, 2025
AI Mini Challenge: Technical Reflection
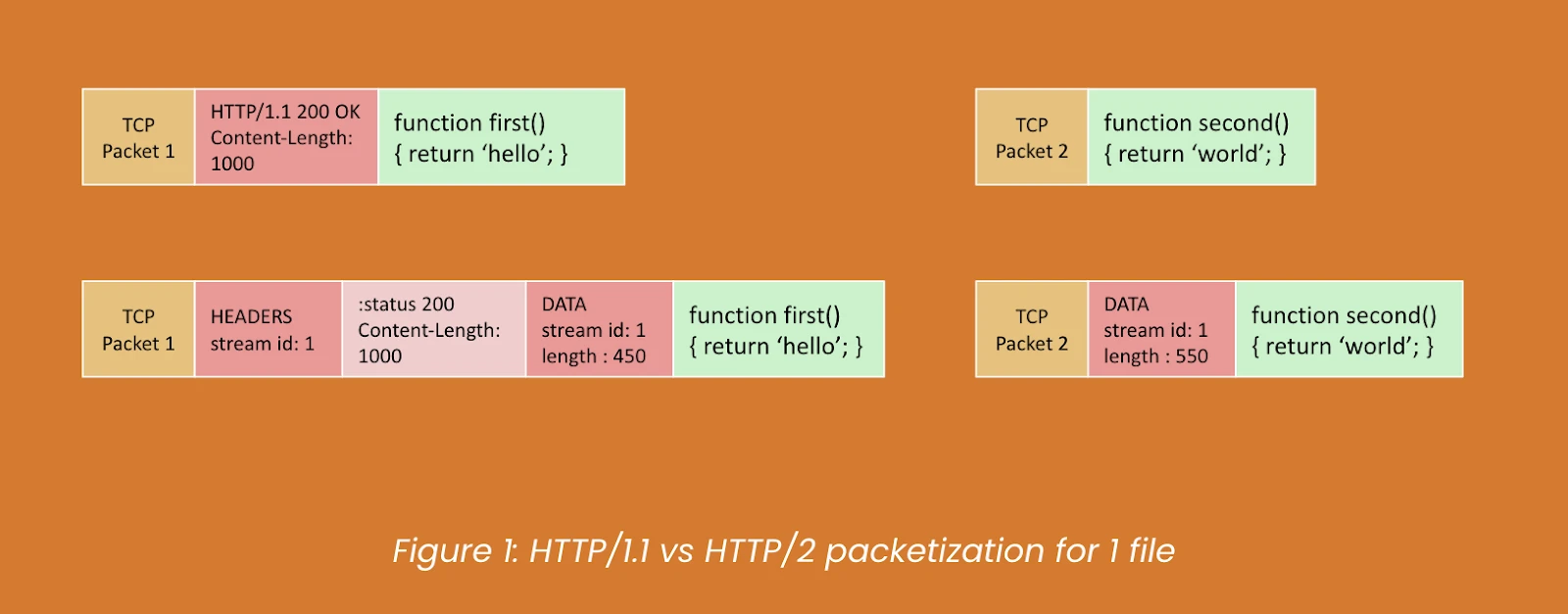
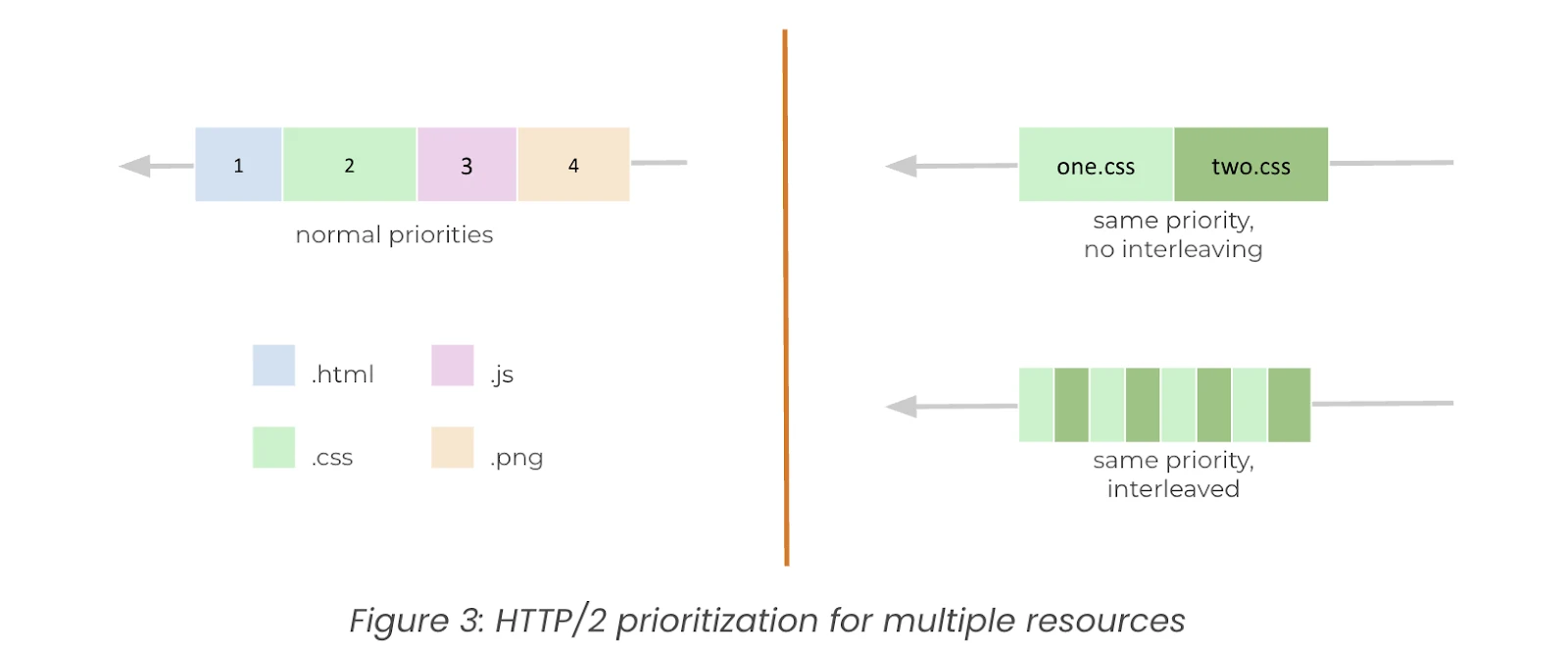
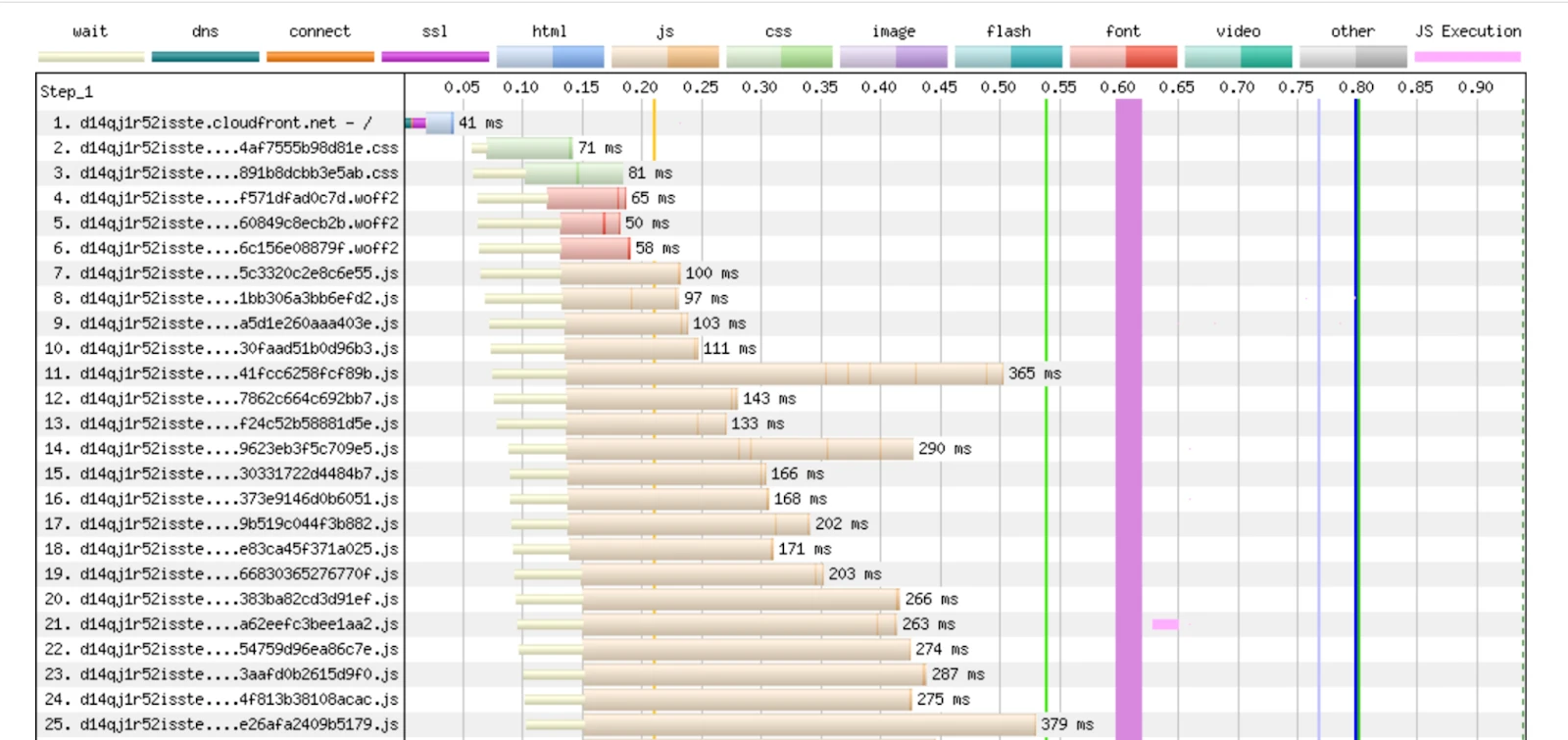
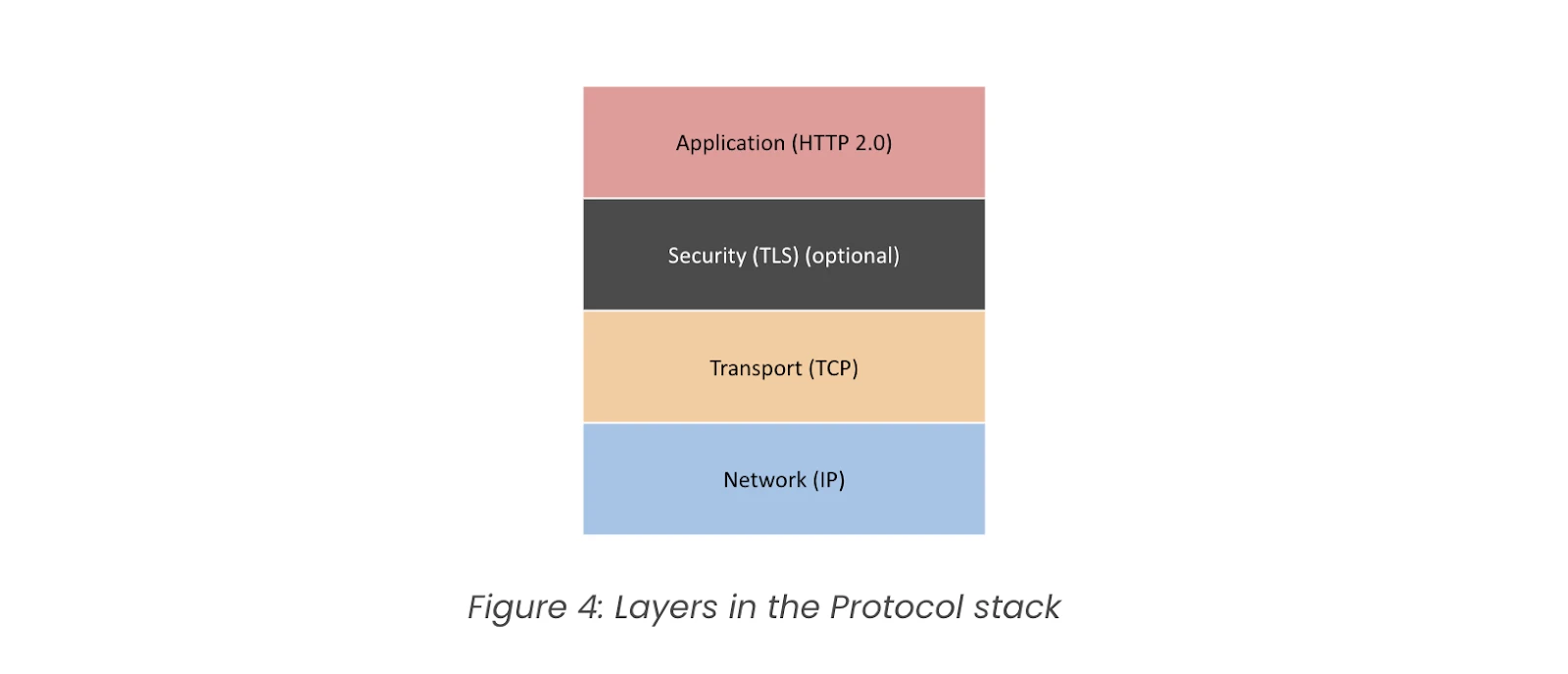
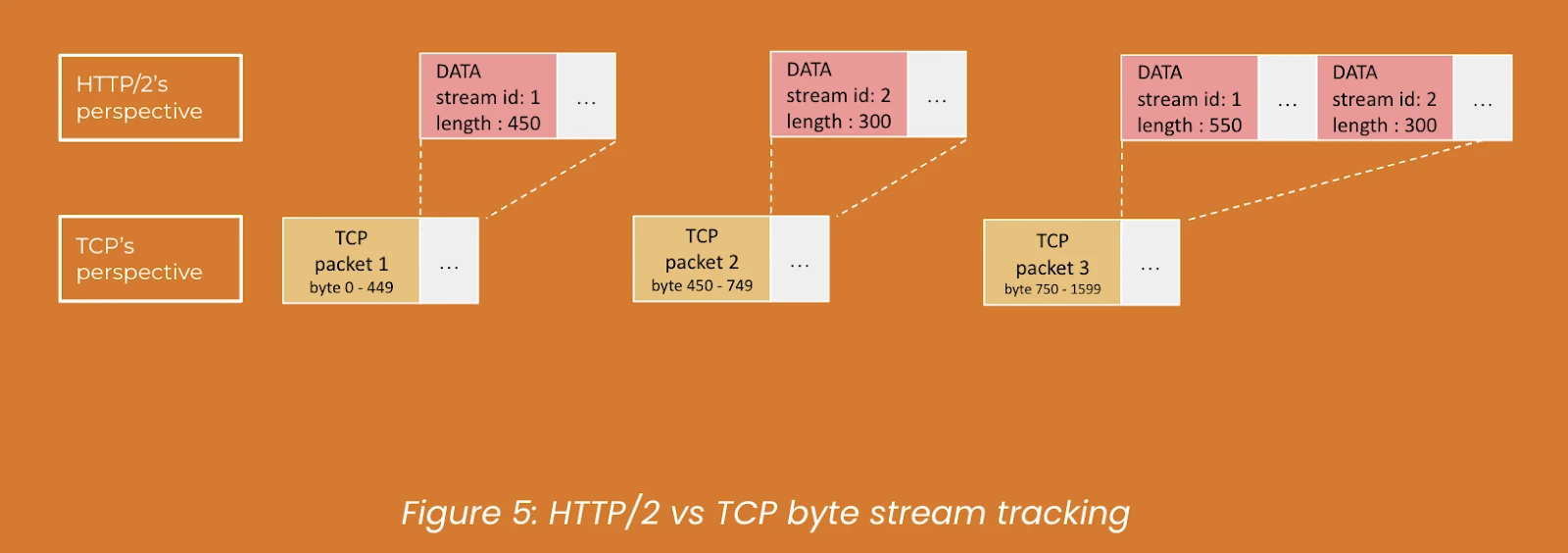
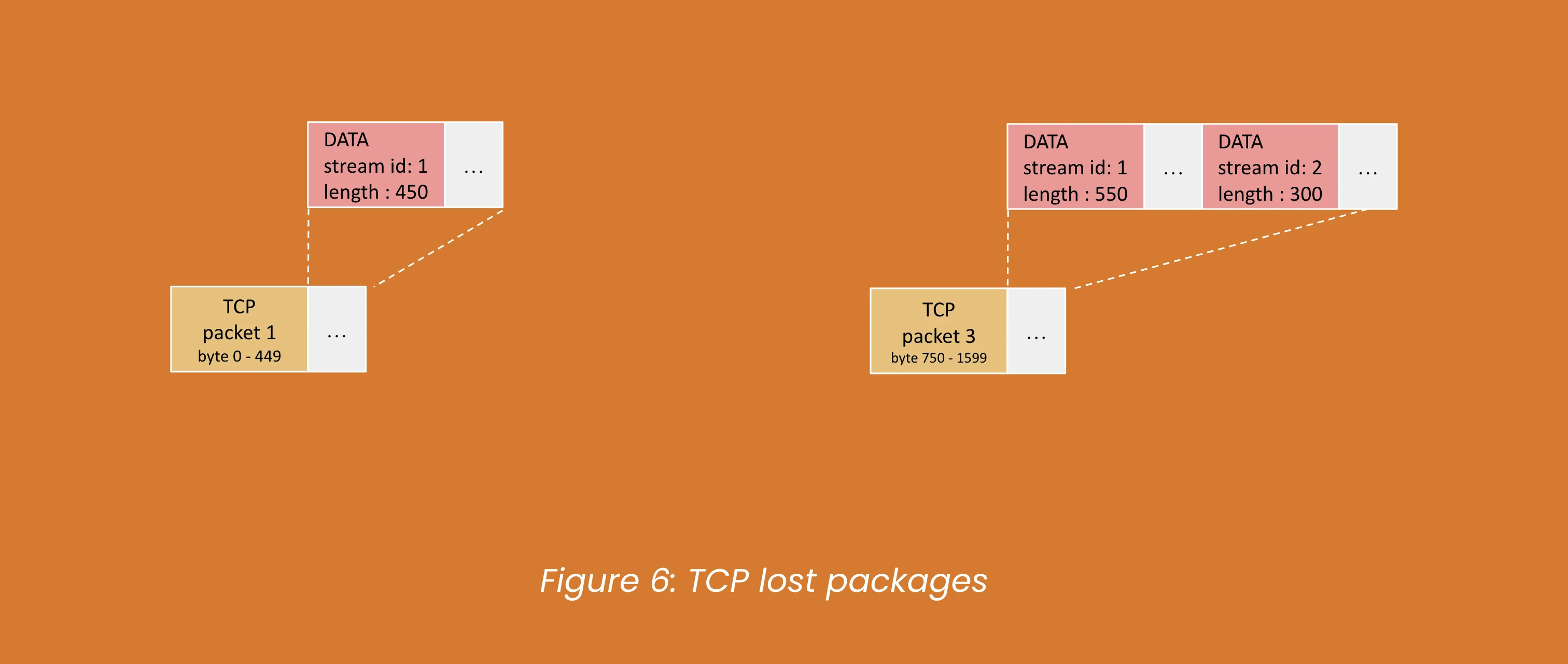
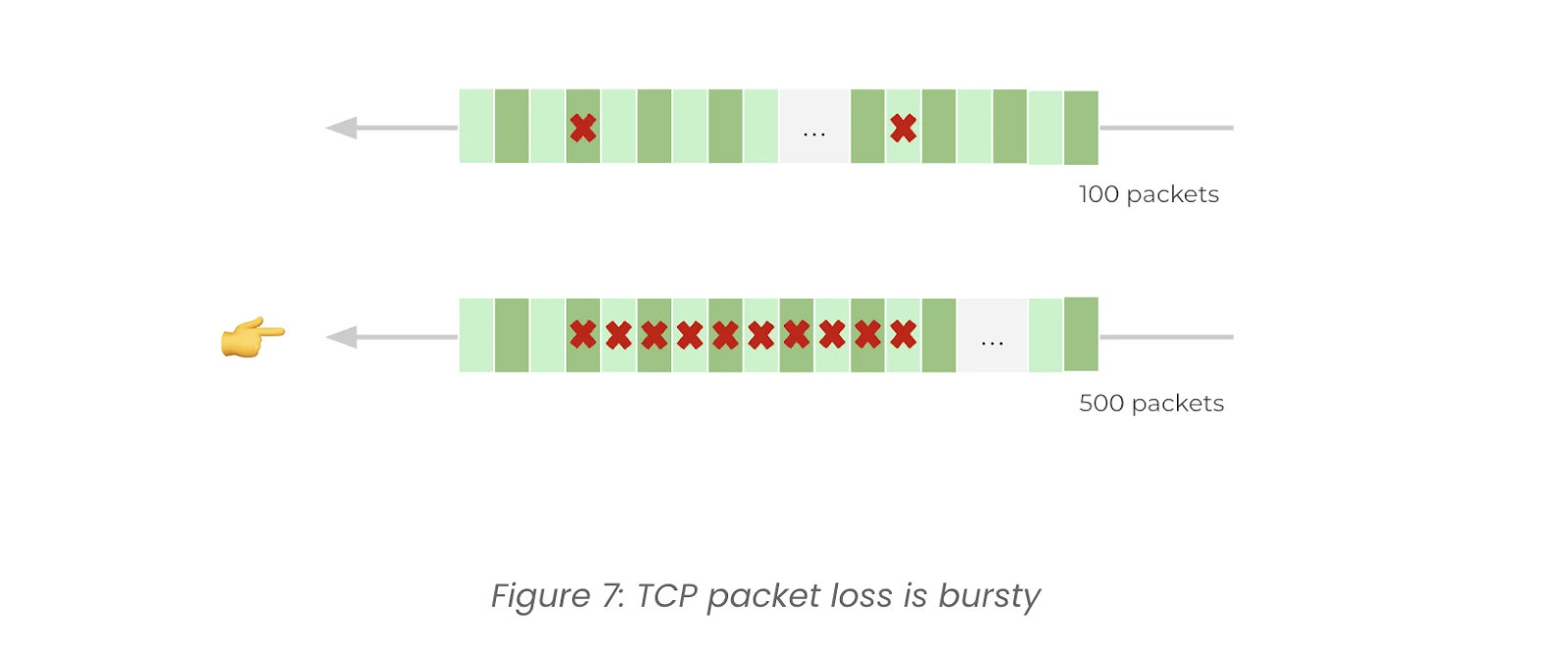
1. IntroductionThe realm of Artificial Intelligence is constantly evolving, presenting new challenges and opportunities for innovation. At Money Forward, we're always eager to push the boundaries of what's possible, and the recent AI Mini Challenge presented a fantastic opportunity to do just that. This internal competition challenged teams to explore and implement AI solutions to real-world problems. It was an intensive yet incredibly rewarding experience, and we're excited to share our journey and the technical insights we gained.We are a team of engineers at Money Forward who came together for the AI Mini Challenge, bringing a strong mix of backend and frontend expertise. As backend engin

