![HTTP Adventure: [Part I] Head-of-Line Blocking](/images/blog/detail-shape-heading.webp)
![HTTP Adventure: [Part I] Head-of-Line Blocking](https://static-careers.moneyforward.vn/Blog/HTTP%20series/Hapi%20-%20OGP%20Tech%20Blog%20Template.png)
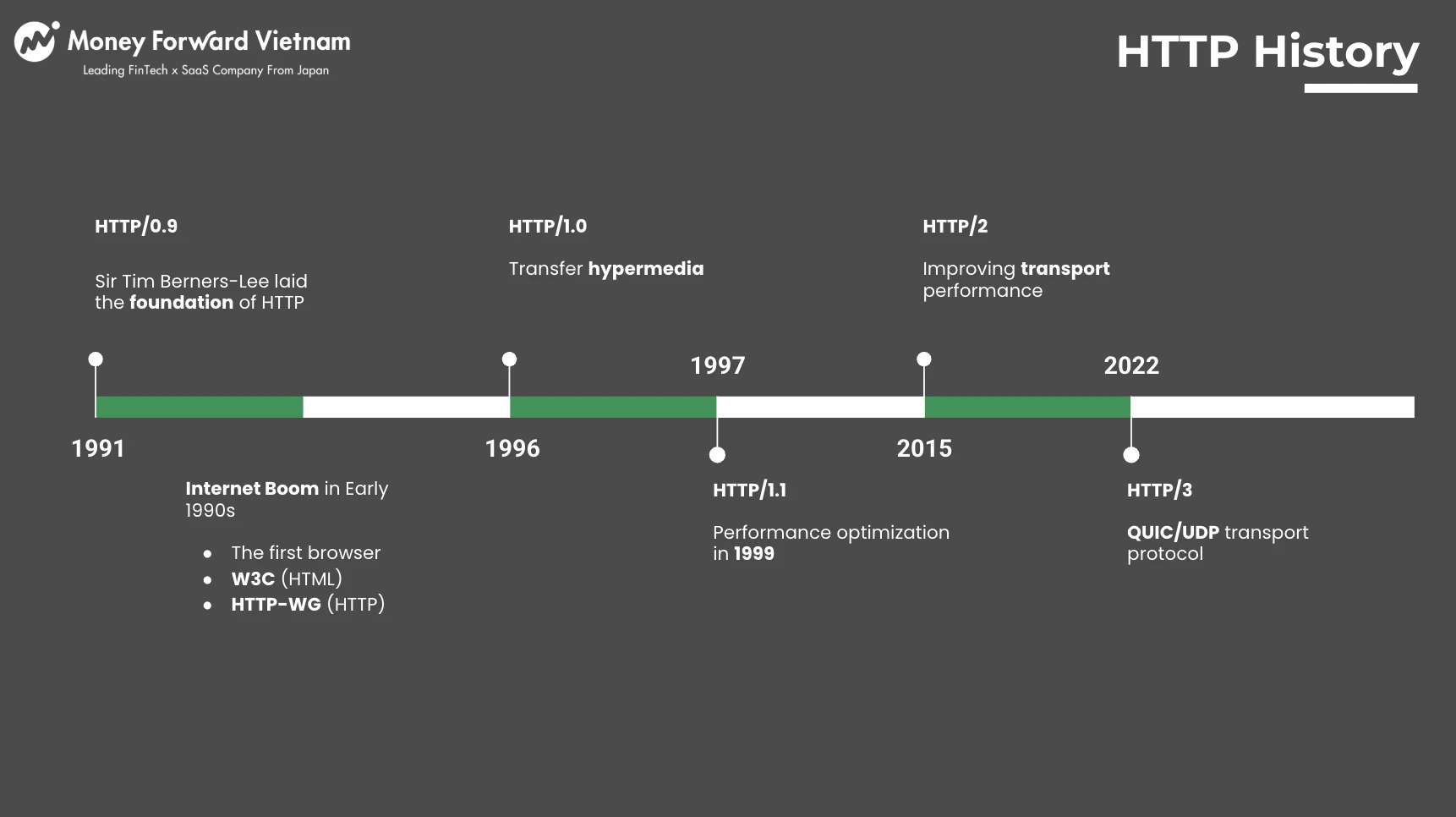
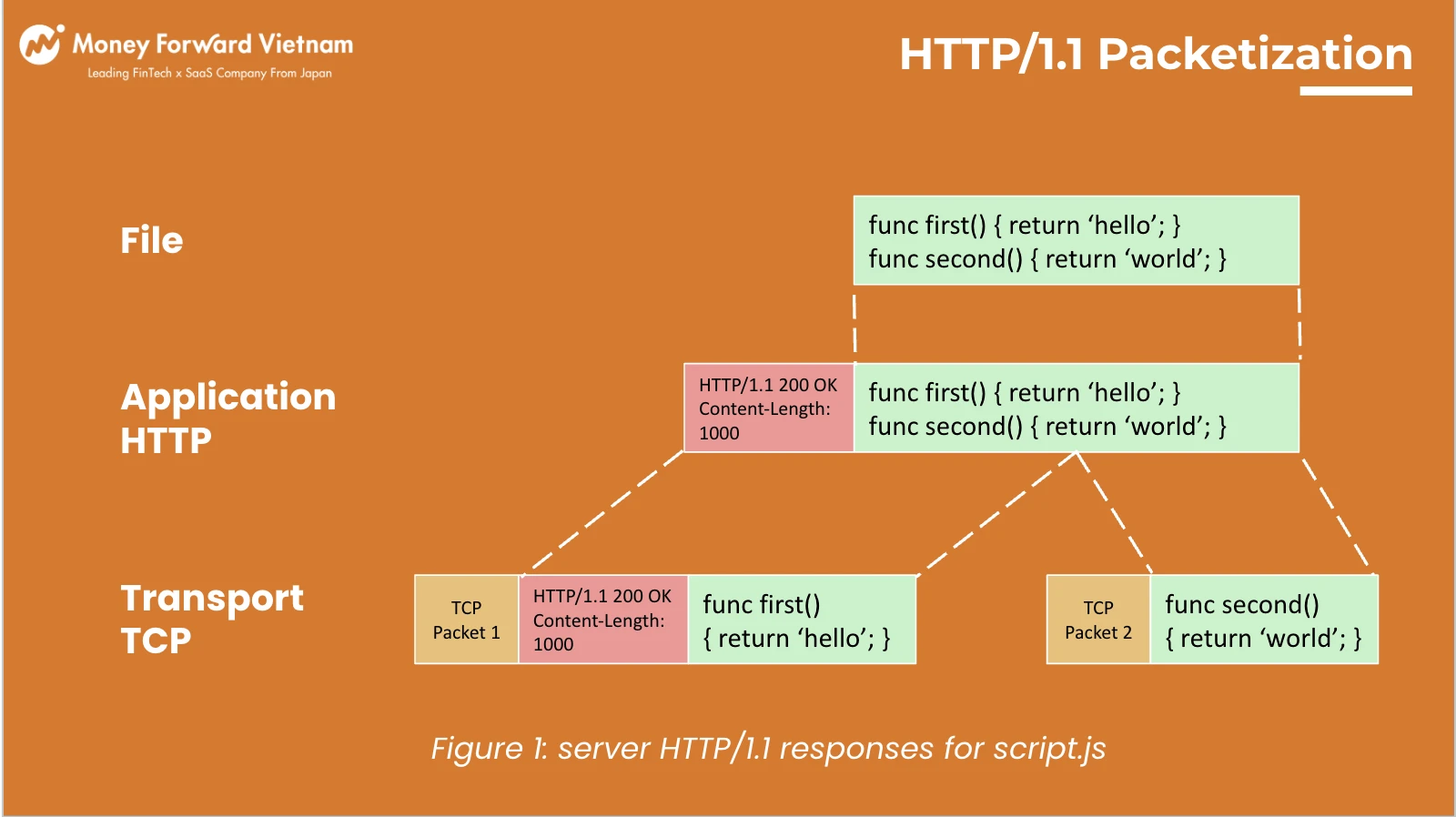
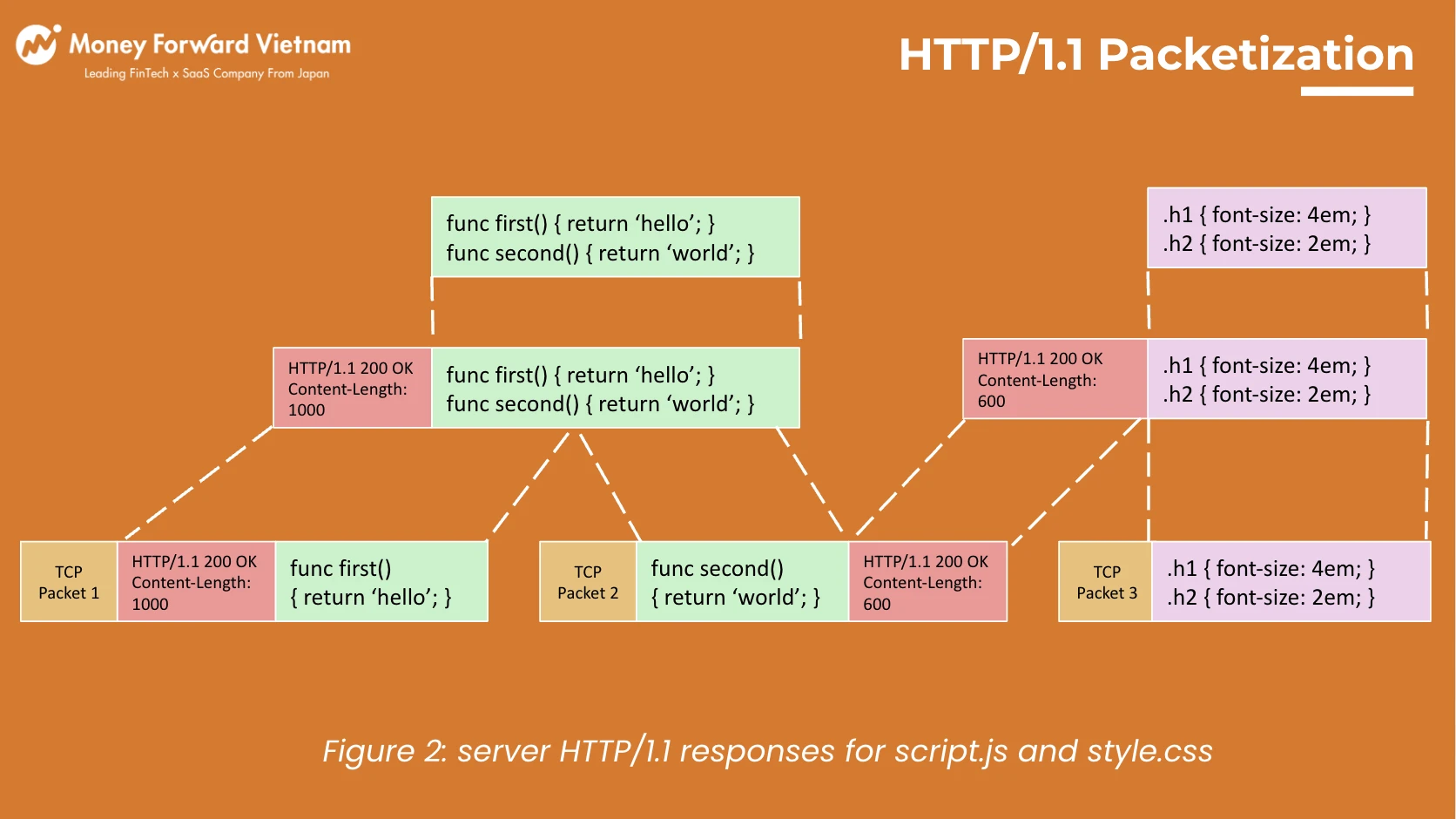
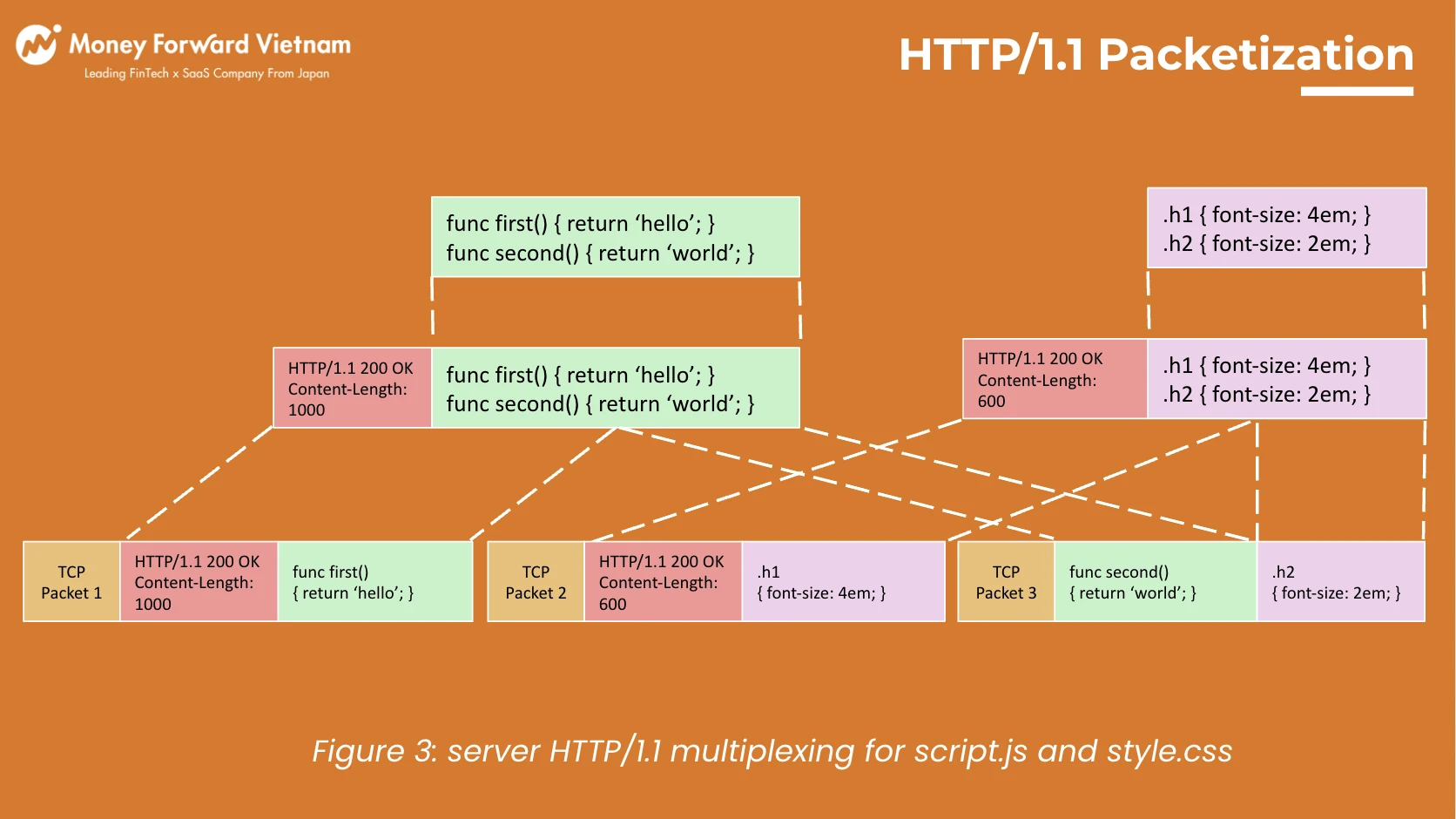

Jun 15, 2022
Jun 15, 2022
Bug Bash? How To Run It?
1. What is Bug Bash:
Nowadays, even though we have a lot of advancement in development methodologies and testing techniques, there is still a big gap in the testing quality between the actual result and expected outcome. This leads t...

