


Oct 26, 2023
Oct 26, 2023
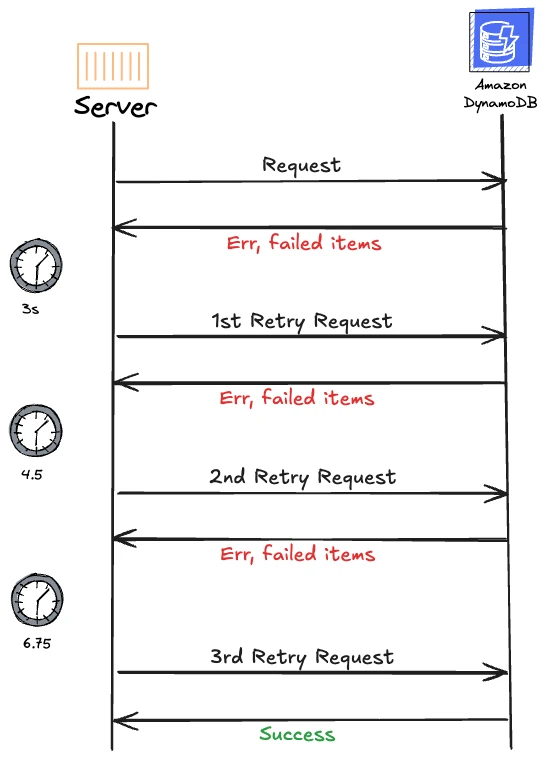
How to determine the appropriate concurrency number in your background job system?
Hello everyone, I'm Reacher from the TA team and I'm the backend developer. I primarily work with Ruby on Rails. Today, I would like to share a topic on how to determine the appropriate concurrency level in your application.

