.png)
Apr 09, 2024
Apr 09, 2024
MFV Tech Talk #3 - Microservice Architect | Hill
This sharing is extracted partly from Hill, a principal back-end engineer from MFV Ha Noi, sharing his team project and microservice architect.


Hello everyone,
This article was written by me, White, a Senior QA Engineer working at Money Forward Vietnam. In this article, I would like to deliver some interesting and useful figures in the Automation Test.
What we will go through
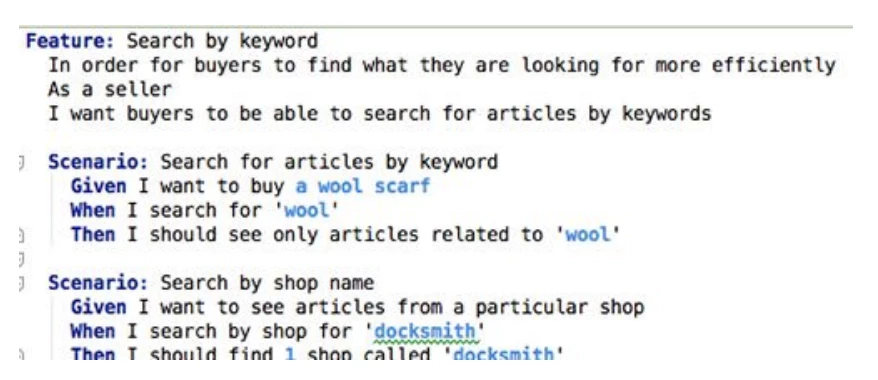
Serenity BDD is a framework. The term BDD stands for Behavior Driven Development, which describes the behavior of an application that is using Gherkin language by plain text. And it‘s inbuilt with the Cucumber tool that allow us to create automation test cases that met with test requirement, here is an example:
BDD is an open source so it is totally free, and could be:
The framework itself is already divided into Cucumber format including failure screenshot, login, result notification email, and the report flag, ...
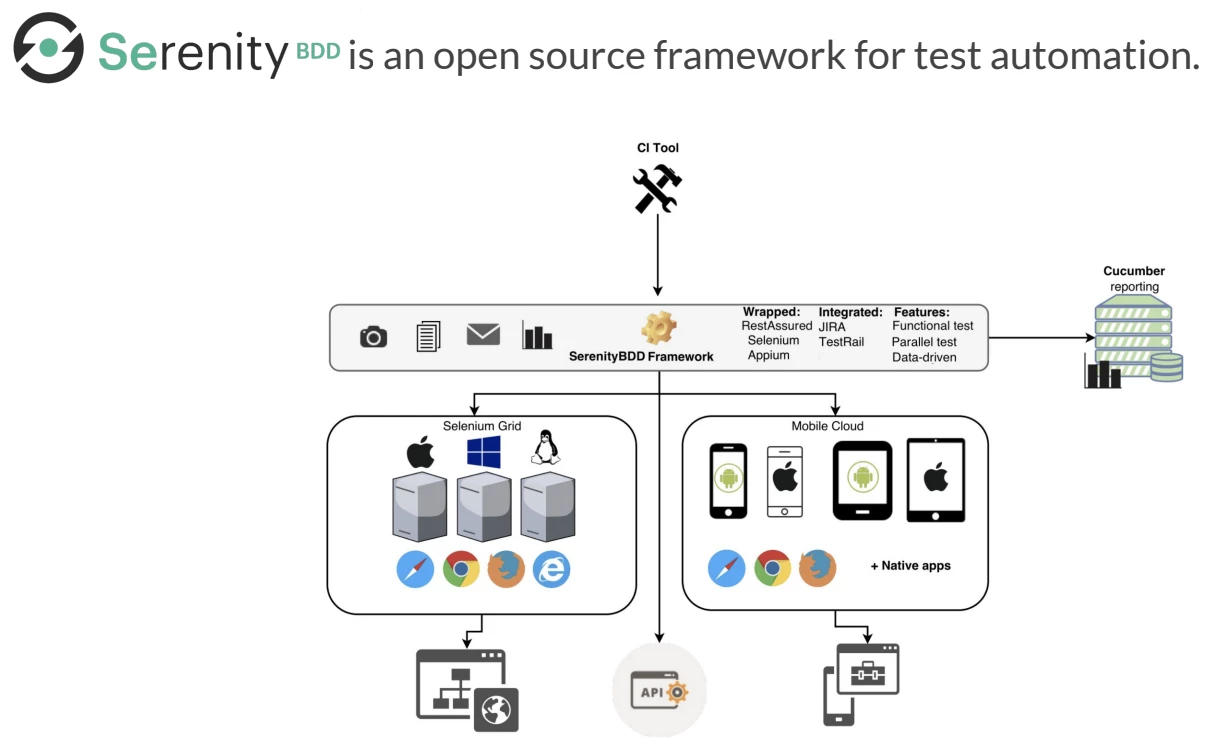
Speed
It already wraps the Selenium Appium, and RestAssure, we just need to set up basic environment namely Java, Maven, IPE, etc. Thus, it can help for faster script development and less maintenance effort on the reusable common step.
Integration
It can be easily integrated with some test management tools like Jira, TestRail, etc. And the CI tool for CICD integration: Jenkins, CircleCI…
Test coverage
This perk provides us with a better way to test quality by facilitating integrate with 3rd parties. By that, the framework gives us more validations for our application.
Fitness Serenity BDD is suitable for both QA with Hybrid and Manual QA

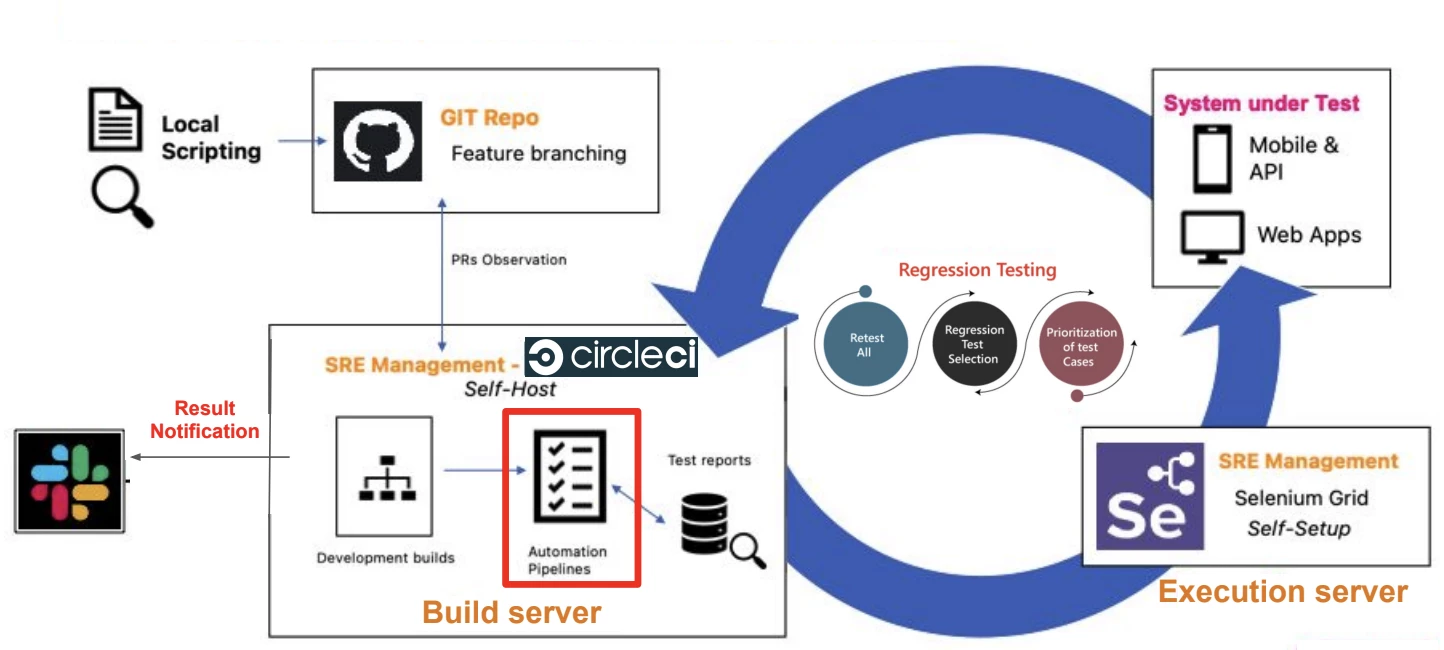
Below is the Automation system run in MFV.
The chart beneath contains 4 main entities.
Basically, we have 2 methods to trigger the Automation Pipelines:
First: when we initiate the local scripting by the QA, the test script will be committed to the Git repository and the pull request will be generated. Circle CI observes the pull request and triggers the pipeline to verify the pull request, then creates a connection to the execution server to run the test. Afterward, the report is generated back to CircleCI, and push the result notification.
Second: when our development team finished the staging deployment, then it will trigger the automation pipelines automatically to run the steps circle as I described above.
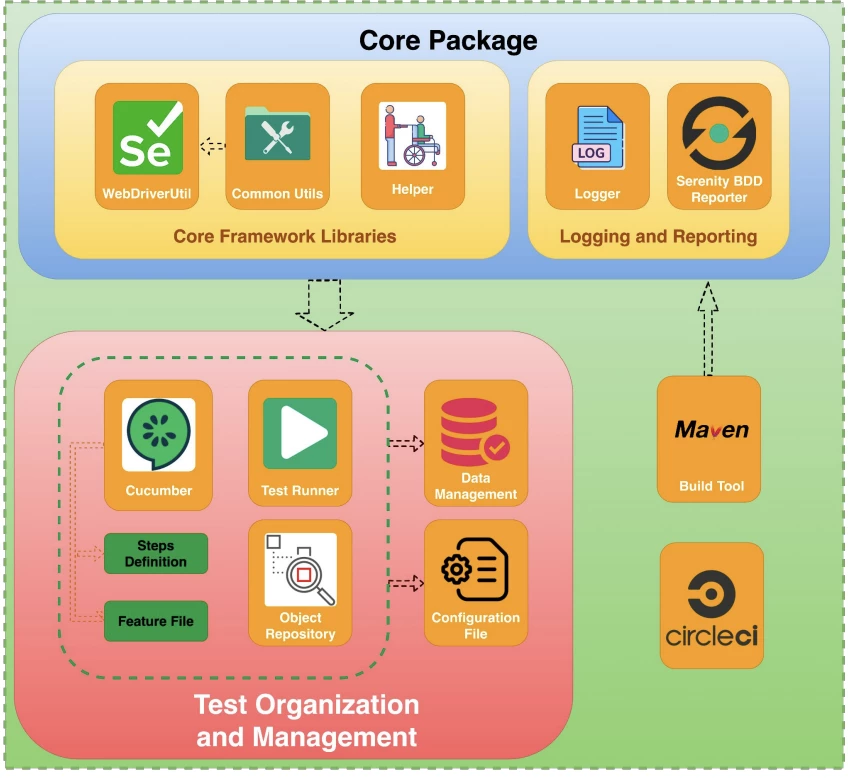
Basically, we have 2 main components: the Core package, Test Organization and Management.
The Core Package contains the Core Framework Libraries. These libraries support us to interact with web elements and browsers as well by using the web driverUtil.
We also have the common Util to help you handle the different kinds of data objects in Java. We have a helper to support us in Framework handling, logging, and reporting Serenity.
For The Test Organization and Management, we have a Feature File to start the test cases and other common tests. We have Steps definitions in the test script in Java language.
We have the Object Repository to start the web element locators and we have the test runner to specify which test should be executed. The Cucumber itself already is the test data but we also have the data management to load the external data file like Jason or Excel or CSV.
The next one is the Configuration File to start global variables or the environment variables which can be accessed anywhere in our test script.
The last one is the Maven file containing the Dependency.
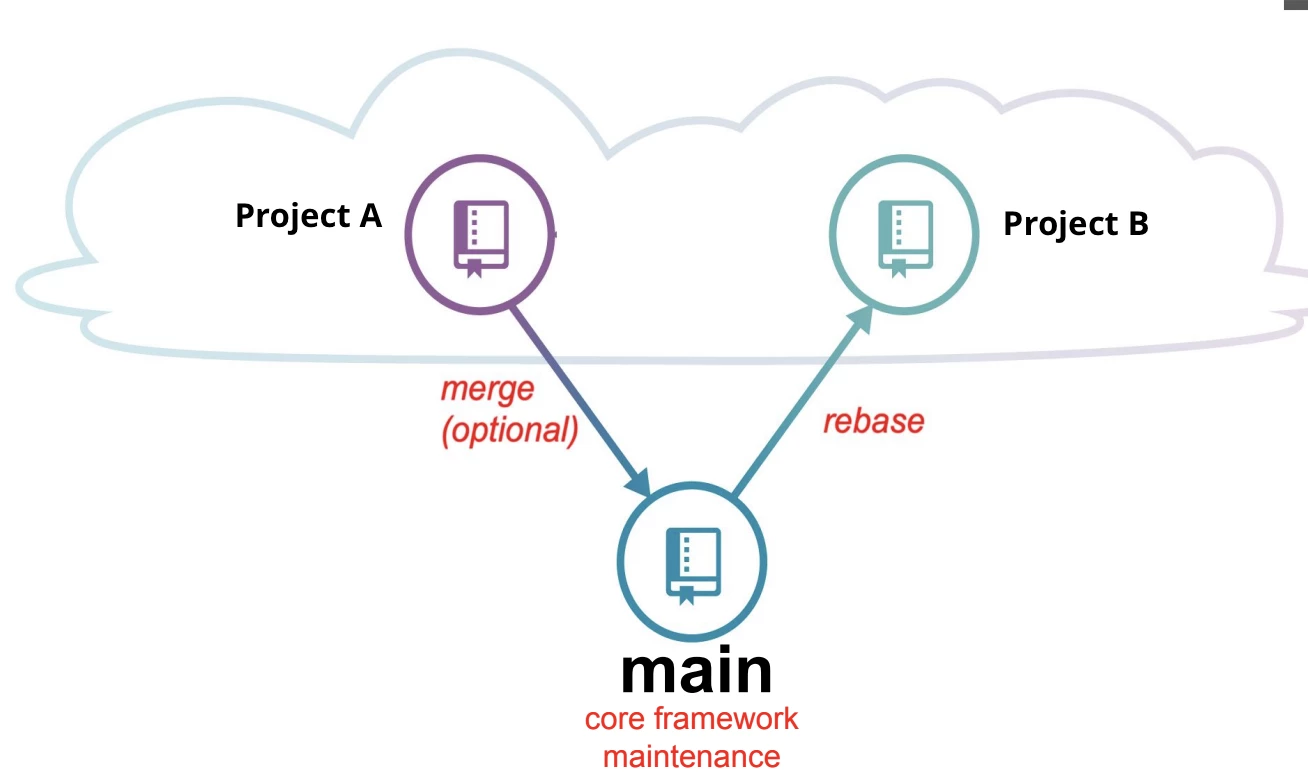
The above picture shows us how to branch in our Git Repos. We have a main branch for Core Framework Maintenance only. When a new project in our organization needs to apply automation testing, automation core team will support closing the main branch into the project branch like Project A and Project B.
And then CircleCI will establish the connection to the project branch for the Project A cushion. Apart from that we also have a station branch allowing our QA to submit their code for previewing before matching into the project branch.
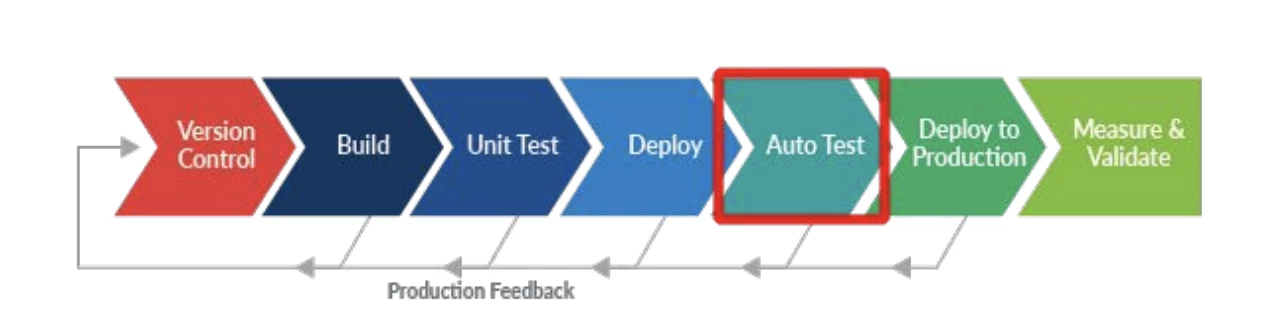
For CI integration, the auto test stays between the station deployment and production deployment to verify the production impact before deploying the new feature to production.
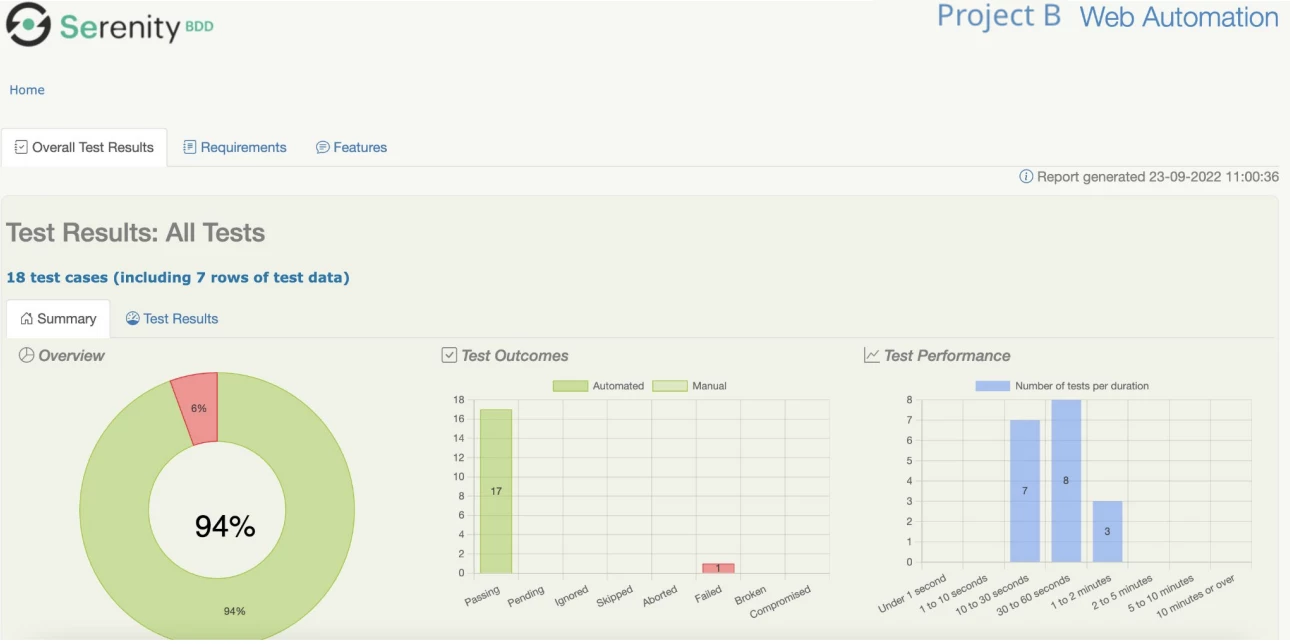
This is the example result of pipeline execution. As you can see here we have the step result of the pipeline, a result notification will be sent via, for example, your Slack channel. If you click the view details report here you will see the first one is the summary report showing all the exclusion statuses and we have some other graphs.
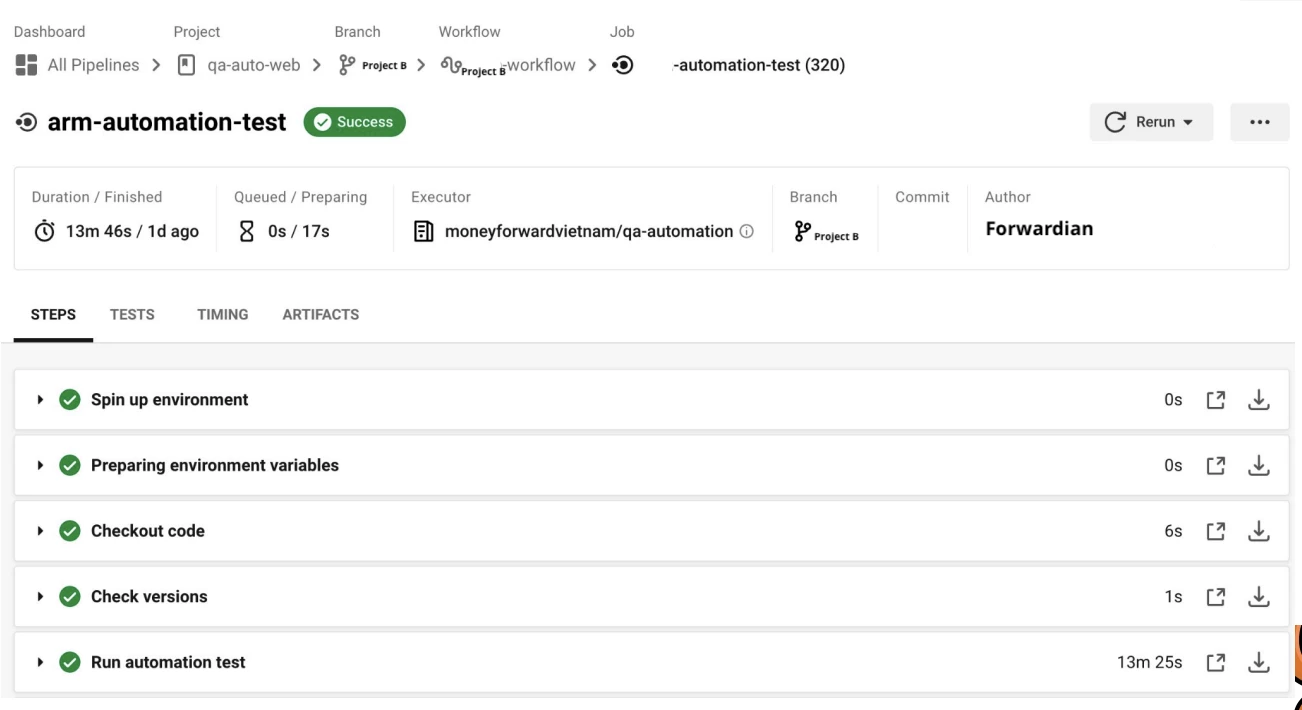
This is a detailed report on features and cases we have the feature name and the test cases name. The executed steps start time, duration, and result.
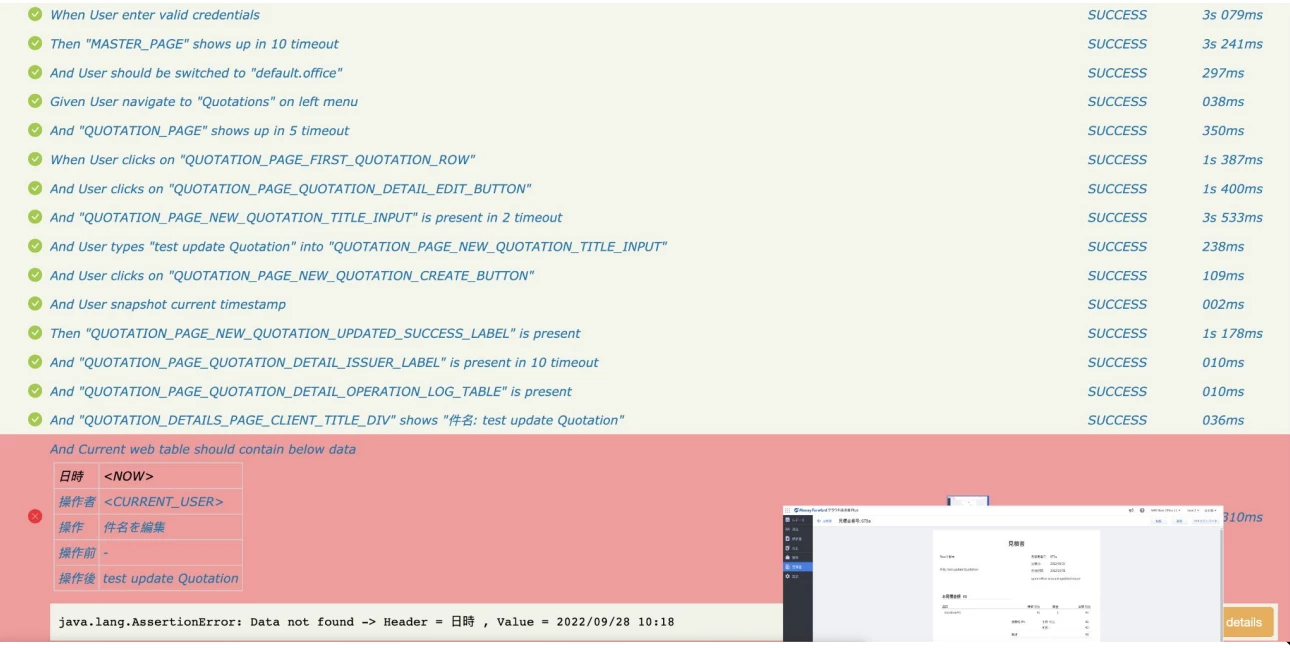
This is the detailed result for each step, so If we have any failed step it will be highlighted in red here with login and failure screenshot, and logging as well.
That‘s all for the brief introduction, hope you can have gained a new method to deliver better-qualified products to our users.
Author: White
Transcriptor: Michael
Editor: Jim

