






Jul 23, 2025
Jul 23, 2025
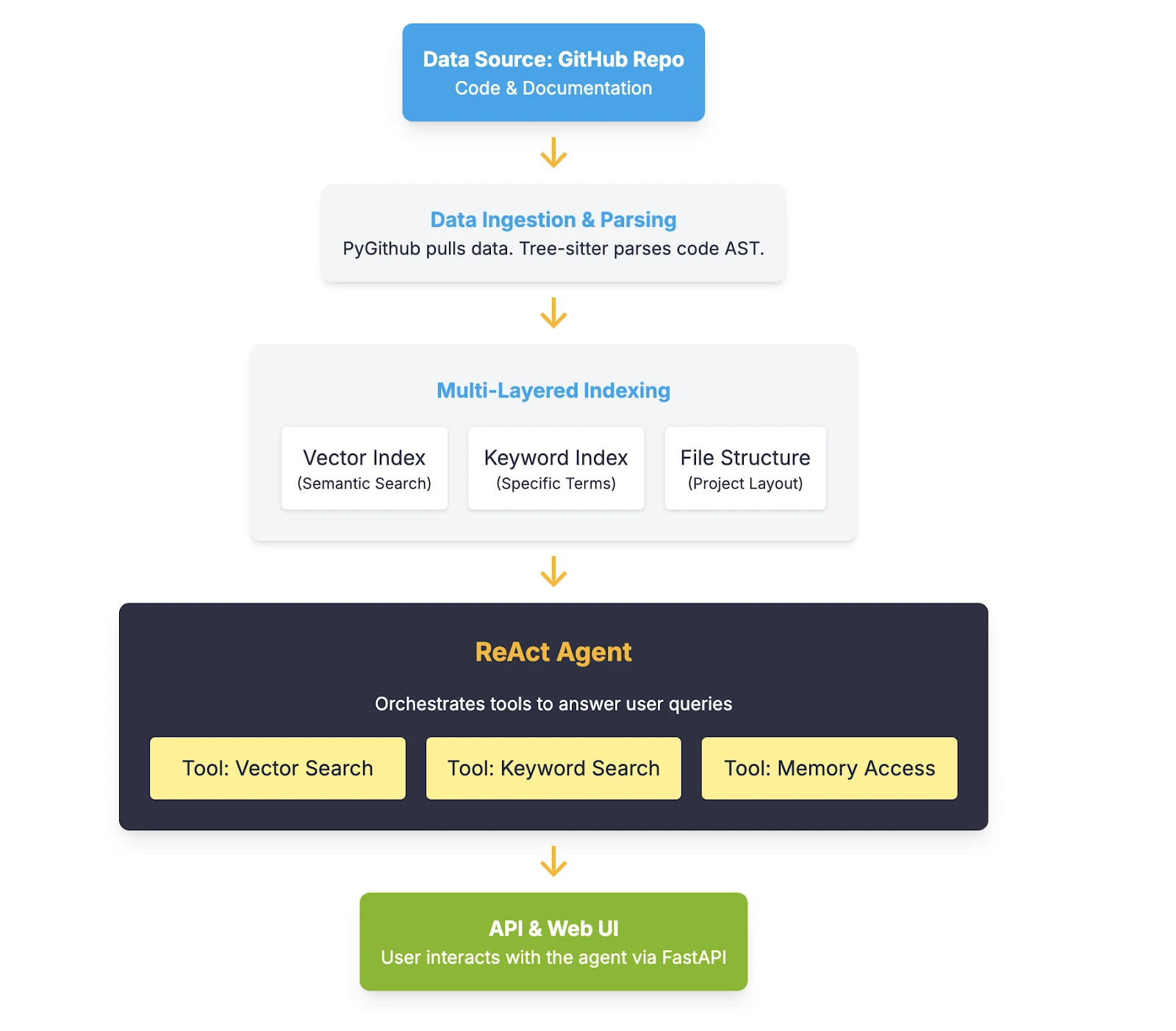
MFV AI Mini Challenge: Lessons Learned
The MFV AI Mini Challenge, which concluded on June 27th, marked not an end, but a significant beginning in MFV's journey towards integrating Artificial Intelligence into its core operations.

